
Simulating Magnetic Fields of Arbitrary Meshes using Radia and TetGen
Posted on
Tags: Opt-ID, Synchrotron, Magnets, Computer Graphics

Image of a tetrahedralized Stanford Bunny simulated as if it were made of a vertically magnetized metal. The magnetic field is visualized by starting a number of stream curves at random locations around each of the vertices within the tetrahedral mesh of the bunny, and integrating them forwards and backwards through the magnetic field in small steps.
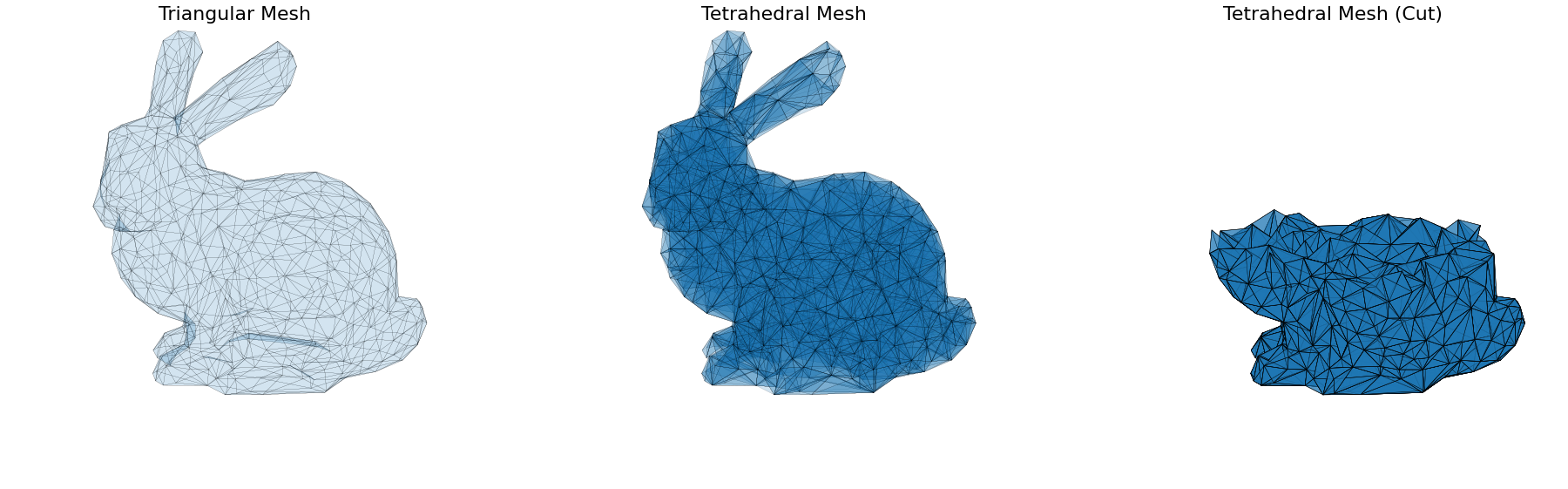
The magnetic field was simulated using the Radia magnetostatics framework by Oleg Chubar.
Tetrahedral meshing was perfromed from a triangular mesh of the classic Stanford Bunny using the PyVista TetGen wrapper around Hang Si's TetGen library.
Geometry representation and interfacing between these frameworks was performed using the Opt-ID framework as a means of testing its versatility for handling exotic magnet geometries.

Continue Reading
Visualizing the Growth Pattern of a Poisson Disk Sampler
Posted on
Tags: Computer Graphics
This project was inspired by the fantastic pen plotter visualizations created by Michael Fogleman.

Poisson Disk Sampling is a technique for drawing batches of blue noise distributed samples from an n-dimensional domain. The method works by selecting an initial, seed, point and proposing k (the branching factor) random points within 1 to 2 radii r of the initial point. For each of these proposal points we test whether they are closer than the threshold radius r from any of the accepted points (initially just the seed point). If the point is far enough away from any of the accepted points, it becomes accepted, and we sample k new points around it for later processing. If the point is too close to another accepted point it is immediately discarded.
By continuing the process for a given number of accepted points, until the n-dimensional space can no longer be filled without points being closer than the threshold r, or some other criteria is met we end up with a set of well distributed points that have nice mathematical properties when used in stochastic approximation methods.
An interesting observation is that the set of sample points is "grown" outwards from the seed point, and that each accepted point can trace its origin to a single parent point which spawned it. If we connect the sampled points as a tree hierarchy we can visualize the growth pattern of sample set as a tree.
The implementation I used to generate the above image used the sampling algorithm described in Fast Poisson Disk Sampling in Arbitrary Dimension, Robert Bridson 2007 which can produce batches of well distributed samples in O(n) computation time.
I have released the code for this project open source as a jupyter notebook. The main bottleneck in this code is actually the line plotting of the sample tree due to limitations of Matplotlib. With a better method of drawing the generated trees larger and deeper growth patterns could easily be visualized.
Continue Reading
AC-GAN, Auxiliary Classifier Generative Adversarial Networks
Posted on
Tags: Machine Learning, Computer Graphics
In this project I implemented the paper Conditional Image Synthesis With Auxiliary Classifier GANs, Odena et. al. 2016 using the Keras machine learning framework.
Generative Adversarial Networks, Goodfellow et. al. 2014 represents a training regime for teaching neural networks how to synthesize data that could plausibly have come from a distribution of real data - commonly images with a shared theme or aesthetic style such as images of celebrity faces (CelebA), of handwritten digits (MNIST), or of bedrooms (LSUN-Bedroom).
In GANs two models are trained - a generative model that progressively learns to synthesize realistic and plausible images from a random noise input (the latent vector) - and a discriminative model that learns to tell these generated (fake) images from real images sampled from the target dataset. The two models are trained in lock-step such that the generative model learns to fool the discriminator model, and the discriminator adapts to become better at not being fooled by the generator.
This forms a minimax game between the two models which converges to a Nash equilibrium. At this point the generator should be able to consistently produce convincing images that appear to be from the original dataset, but are in-fact parameterized by the latent vector fed to the generative model.
Auxiliary Classifier GANs extend the standard GAN architecture by jointly minimizing the generators ability to fool the discriminative model, with the ability of the discriminator to correctly identify which digit it was shown. This allows the generative model to be parameterized not only by a random latent vector, but also a representative encoding of which digit we would like it to synthesize.
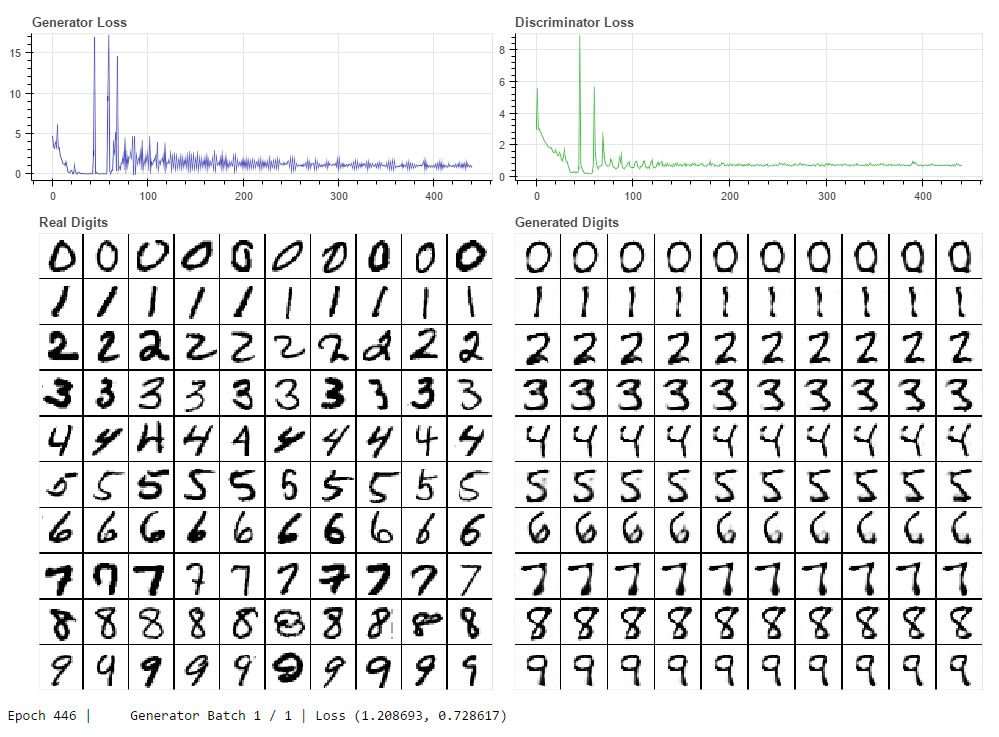
The above image shows the result of my AC-GAN implementation trained on the MNIST dataset. On the left we see real images sampled randomly from MNIST for each of the 10 digit classes, and on the right we see images synthesized by the generative model for each class. The generated images are not sampled completely randomly, in this image I was selecting a random value of the latent vector and sweeping it from a value of 0 to 1. We can see that for each digit class the had the subtle effect of adjusting rotation and "flair" or perhaps "serif-ness", showing that the generative model has mapped the space of possible values that exist in the latent vector to different stylistic traits of the produced digits.
The results of this experiment are satisfying but not great overall. I believe the model suffers from, at least partial, "mode collapse" where the generator learns to produce a subset of possible stylistic variations convincingly and so never attempts to learn how to produce other stylistic variants.
Since the publication of Goodfellow's seminal work on GANs many variations have been proposed that attempt to solve common issues such as mode collapse and training stability.
In the future I plan to revisit this project and implement some of the newer and more advanced methods. While the code for this project is written as a jupyter notebook I do not plan to release the code as it is not very clean or well documented. I will however release well documented code when I revisit this project.
Continue Reading
Neural Artistic Style Transfer
Posted on
Tags: Machine Learning, Computer Graphics
In this project I implemented the paper A Neural Algorithm of Artistic Style, Gatys et. al. 2015 using the Keras machine learning framework.

Cat photo credit: Claire Whittle
My implementation was loosely based on the fantastic Keras example code by Francois Chollet. In my implementation I modifed the VGG19 architecture using pre-trained weights trained on ImageNet. I replace the maximum pooling layers with average pooling using the same strides and discard the fully connected layers at the end of the network as they are not needed and take up unecessary memory on the GPU.
In Francois' code he makes use of the SciPy L-BFGS optimizer. While this produced nice results in a small number of iterations I found that the high memory requirement of L-BFGS (even though the L stands for Limited-memory) was prohibitive in producing images of a resolution higher than around 400x400. Through experimentation I found that the SciPy Conjugate Gradient optimizer provided good results with greatly reduced memory complexity, allowing me to raise the resolution of produced images to around 720p on a single NVidia 870m GPU.
I plan to revisit this project in the future implementing it entirely in Tensorflow. I may also investigate newer and more advanced methods that have been proposed since the publication of Gatys' seminal paper in this area.
Full code for this project is available here as a Gist.
In the remainder of this post I will show some of the images that I produced with the linked code.

Boat photo credit: John Whittle

Boat photo credit: John Whittle

Cat photo credit: Claire Whittle

Cat photo credit: Claire Whittle

Cat photo credit: Claire Whittle

River photo credit: Taken from the original paper

River photo credit: Taken from the original paper

River photo credit: Taken from the original paper.

River photo credit: Taken from the original paper
Continue Reading