
About Me
I am a Research Software Engineer at the Rosalind Franklin Institute working on combinatorial optimization of magnetic systems used to build Synchrotron Insertion Devices.
Formerly I worked as a PostDoc Computer Graphics and Machine Learning researcher at the University of Swansea in the United Kingdom.
Thesis
In February, 2018 I completed my PhD thesis studying the robustness of Image Quality Assessment metrics when applied to images generated through stochastic processes such as Monte Carlo rendering algorithms. In this work I also study the use of machine learning methods, applied to the task of No-Reference Image Quality Assessment on Monte Carlo rendered images, where we wish to evaluate the predicted quality of images without having access to their final (true) values.
Research Interests
My research interests are focused around the intersection between physically based (photo-realistic) rendering methods and machine learning techniques such as deep convolutional neural networks. As a necessary prerequisite for much of this work I also have a vested interest in the field of high performance computing, encompassing both distributed computing on clusters and massively parallel computing on accelerator devices such as GPU and co-processors.
A list of my research publications can be found here.
Physically Based Rendering
With respect to computer graphics, my research is centered around the use of stochastic approximation through Monte Carlo sampling methods to approximate the rendering equation [Kajiya, 1986]. This is mostt often realized via a family of ray tracing algorithms based on path tracing.
The following image, generated using a renderer developed during my PhD, is an example of bidirectional path tracing. Here we simulate the interactions of light coming from a diffuse area light source, scattering through a glass model of the Stanford Bunny which I have modified to have both inner and outer walls, and have filled with a simulated wine like liquid. In the foreground, within the shadow of the bunny, we can see caustic illumination patterns where light has been tinted and focused as it undergoes refraction as it passes through the glass and liquid mediums. In the background of the image the grid pattern on the floor becomes blurred and out of focus due to the physical simulation of light interactions with a camera aperture and lens elements. Similarly, the aperture simulation can be seen in the form of small hexagonal specular highlights on the bunnies ears which occur due to the aperture being modeled as a six sided polygon.

Unless otherwise specified, all images shown on this website are the products from my research or personal projects.
Machine Learning
With respect to machine learning, my research is currently focused on the use of deep learning methods such as convolutional neural networks to evaluate the quality of physically based images produced through stochastic rendering methods.
Image Quality Assessment, where we wish to quantify the quality of images as perceived by the human visual system poses a difficult and deeply subjective problem. Measures of image quality must faithfully balance the importance of perceived distortions as determined by the psychophysical limitations of the human visual system, with the psychological perception of such distortions determined by factors such as taste and personal preference.
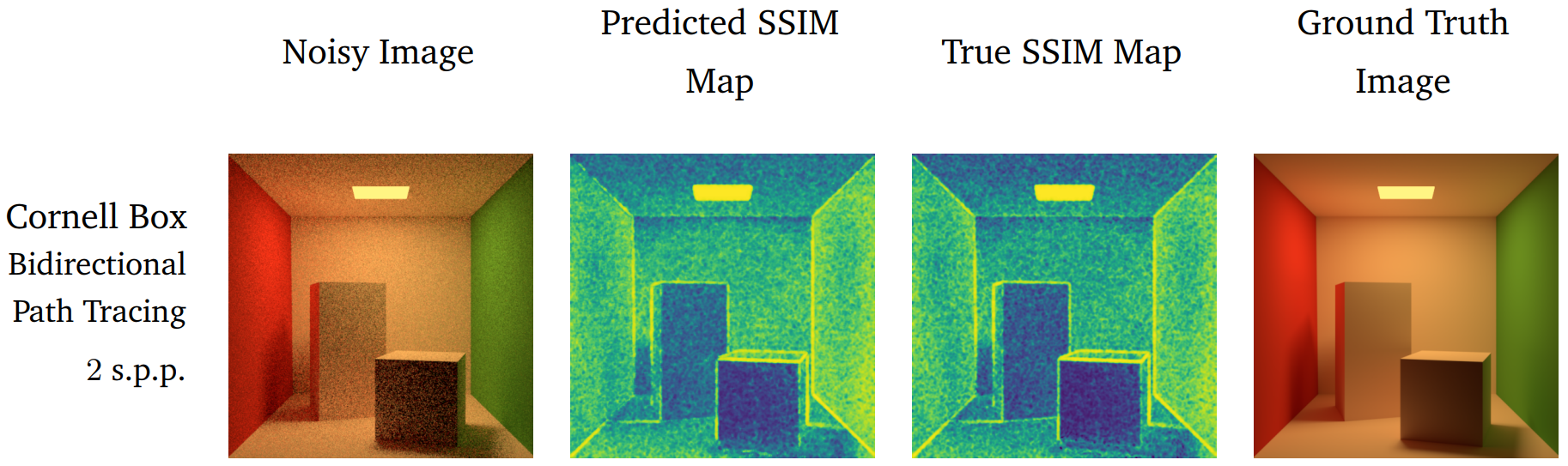
In the image above, from my PhD thesis, we first see an unconverged image of the classic Cornell Box scene which contains a significant amount of visual distortion in the form of impulse noise. This noise is present due to the low sampling rate used to approximate the value of each pixel - in this case, just 2 samples per pixel generated with the naive path tracing algorithm. This image is fed to a deep convolutional neural network which has been trained to predict a representative scalar quality score for each pixel in the input image, yielding the predicted SSIM quality map shown in the second image. The third image shows the true SSIM quality map that is computed by using both the unconverged image and a high quality converged version known as the ground truth or reference image, which is shown on the right. As we can see, our machine learning based method is able to faithfully capture the distribution of naturally occurring distortions within the unconverged image without having access to the ground truth image.
During the rendering process we often do not have access to the final ground truth image - if we did, we would likely not need to finish rendering the unconverged image, we could just use the ground truth we already have. In such scenarios, the ability to accurately predict image quality as it would be perceived by human observers is an important diagnostic tool for evaluating when images have converged to an acceptable quality, without needing to resort to manual, by-hand, evaluation.