In this project I implemented the paper Conditional Image Synthesis With Auxiliary Classifier GANs, Odena et. al. 2016 using the Keras machine learning framework.
Generative Adversarial Networks, Goodfellow et. al. 2014 represents a training regime for teaching neural networks how to synthesize data that could plausibly have come from a distribution of real data - commonly images with a shared theme or aesthetic style such as images of celebrity faces (CelebA), of handwritten digits (MNIST), or of bedrooms (LSUN-Bedroom).
In GANs two models are trained - a generative model that progressively learns to synthesize realistic and plausible images from a random noise input (the latent vector) - and a discriminative model that learns to tell these generated (fake) images from real images sampled from the target dataset. The two models are trained in lock-step such that the generative model learns to fool the discriminator model, and the discriminator adapts to become better at not being fooled by the generator.
This forms a minimax game between the two models which converges to a Nash equilibrium. At this point the generator should be able to consistently produce convincing images that appear to be from the original dataset, but are in-fact parameterized by the latent vector fed to the generative model.
Auxiliary Classifier GANs extend the standard GAN architecture by jointly minimizing the generators ability to fool the discriminative model, with the ability of the discriminator to correctly identify which digit it was shown. This allows the generative model to be parameterized not only by a random latent vector, but also a representative encoding of which digit we would like it to synthesize.
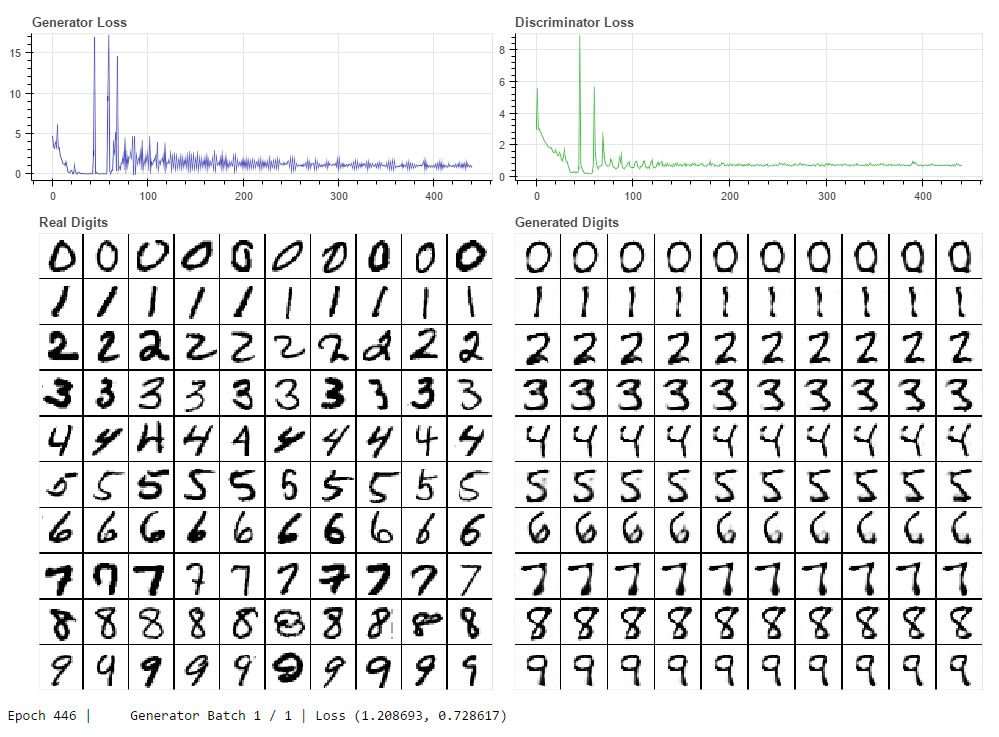
The above image shows the result of my AC-GAN implementation trained on the MNIST dataset. On the left we see real images sampled randomly from MNIST for each of the 10 digit classes, and on the right we see images synthesized by the generative model for each class. The generated images are not sampled completely randomly, in this image I was selecting a random value of the latent vector and sweeping it from a value of 0 to 1. We can see that for each digit class the had the subtle effect of adjusting rotation and "flair" or perhaps "serif-ness", showing that the generative model has mapped the space of possible values that exist in the latent vector to different stylistic traits of the produced digits.
The results of this experiment are satisfying but not great overall. I believe the model suffers from, at least partial, "mode collapse" where the generator learns to produce a subset of possible stylistic variations convincingly and so never attempts to learn how to produce other stylistic variants.
Since the publication of Goodfellow's seminal work on GANs many variations have been proposed that attempt to solve common issues such as mode collapse and training stability.
In the future I plan to revisit this project and implement some of the newer and more advanced methods. While the code for this project is written as a jupyter notebook I do not plan to release the code as it is not very clean or well documented. I will however release well documented code when I revisit this project.